Spark 生产集群性能调优之路
Spark 生产集群性能调优之路
1. Spark Streaming 背压机制
- 推荐配置(默认 false)
--conf spark.streaming.backpressure.enabled=true
--conf spark.streaming.kafka.maxRatePerPartition=8400 # 用于控制吞吐量- 1.1 如何估算设置?例需要
10分钟的吞吐量控制在50,000,000,Kafka 分区是10,计算公式为:
50,000,000 = maxRatePerPartition * kafkaPartitions * 10 * 60(每秒)
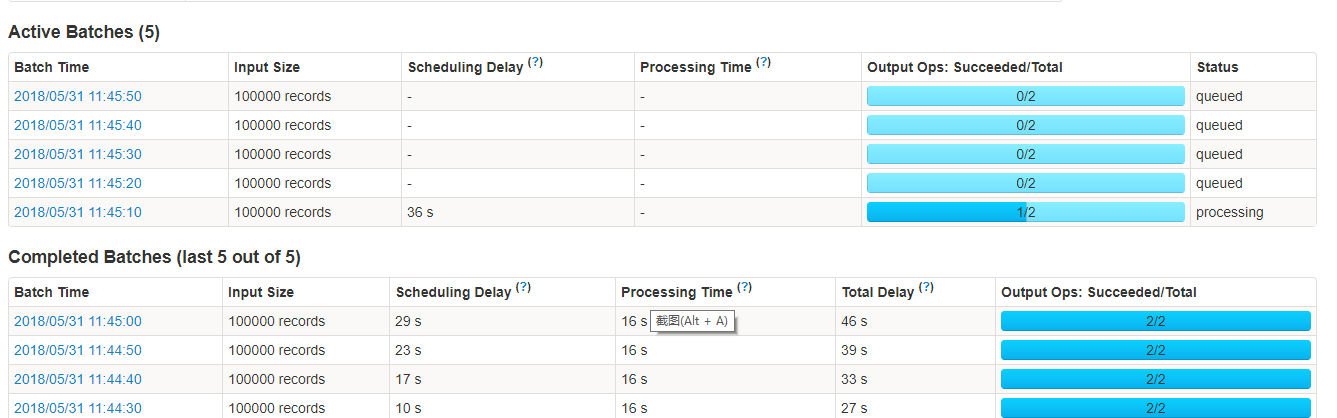
- 1.2 场景:spark streaming kafka 程序首次启动的时候,一般会出现下面的情况。因为有数据挤压,所以会有很多在 queued 状态的 batch。
如果数据量特别大,可能会出问题,因此参数spark.streaming.kafka.maxRatePerPartition就尤为重要,他控制着 Spark Streaming 每秒每个分区最大的消费数量,使得挤压的数据可以慢慢消费。
2. Spark 推测执行机制
-
解决颠簸流量导致数据倾斜,但会降低性能谨慎使用,默认 false;
-
推测任务是指对于一个Stage里面拖后腿的Task,会在其他节点的Executor上再次启动这个task,如果其中一个Task实例运行成功则将这个最先完成的Task的计算结果作为最终结果,同时会干掉其他Executor上运行的实例。spark推测式执行默认是关闭的,可通过spark.speculation属性来开启;
-
注: 亲经历在 spark 2.3.1 时开启推测后,偶尔性报错
ConcurrentModificationException: KafkaConsumer is not safe for multi-threaded access,暂时没有完全证实是这个原因???开启时注意一下
--conf spark.speculation=true
--conf spark.speculation.interval=100
--conf spark.speculation.quantile=0.9
--conf spark.speculation.multiplier=1.8- 2.1. 当spark.speculation设置为true时,就会对task开启推测执行,也就是在一个stage下跑的慢的tasks有机会重新启动;
- 2.2. spark.speculation.interval,100ms,Spark检测tasks推测机制的间隔时间;
- 2.3. spark.speculation.quantile,0.9,当一个stage下多少百分比的tasks运行完毕后才开启推测执行机制,0.9即90%的任务都运行完毕后开启推测执行;
- 2.4. spark.speculation.multiplier,1.5,一个task的运行时间是所有task的运行时间中位数的几倍时,才会被认为该task需要重新启动。
3. Spark 并行度设置
.config("spark.cores.max", "4")
.config("spark.default.parallelism", "2")
.config("spark.streaming.backpressure.enabled", "true")
.config("spark.streaming.receiver.maxRate", "1024")
.config("spark.streaming.kafka.maxRatePerPartition", "256")
.config("spark.streaming.kafka.consumer.poll.ms", "4096")
.config("spark.streaming.concurrentJobs", "2")4. spark on yarn 调度优化
4.1 当并发上来后,经常可能会遇到启动spark streaming程序后会长时间卡在StreamingContext is started上,或者从 spark UI 的大量的 Active Batches (199),再或者运行一段时间后报错 SparkException: Could not find CoarseGrainedScheduler. 可调整 yarn 参数优化:
- capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value> <!-- 默认 0.25,调大可增加 Job 的资源使用率 -->
<description>Maximum percent of resources in the cluster which can be used to run application masters i.e. controls number of concurrent running applications.</description>- yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>